Foreword
This was written many months ago.
In March was the first draft, second draft was in May. It's almost August and I don't think I'm interested in revisiting this to make it even clearer.
I publish it now so it sees the light of day. It is still in a somewhat dirty state but I hope you find it useful nonetheless.
That being said, the basic information is still accurate, and is still applicable and helpful. It is my best knowledge on the subject.
Preface: Pattern?
Yes, pattern.
Software development patterns are naturally reoccurring problems and problem definitions. The fact that people refer to it as just RAG and not "the RAG pattern" is another sign that it is a true pattern, as it is common enough that people just have a word for it that nobody really claimed as a pattern.
"Patterns" have a set of solutions or approaches that are documented by those that have worked on the problem.
The aim of this article is to make you well familiar with the RAG pattern, and its various solutions.
If you're interested in the topic of patterns, the book Unresolved Forces by Richard Fabian is a hefty but valuable read.
Preface: What this article won't cover
For this article, understanding these in depth is not required.
Introduction
First, if you look at LangChain, a very popular resource for RAG and other AI pipelines, you might have run across this diagram in its RAG documentation:
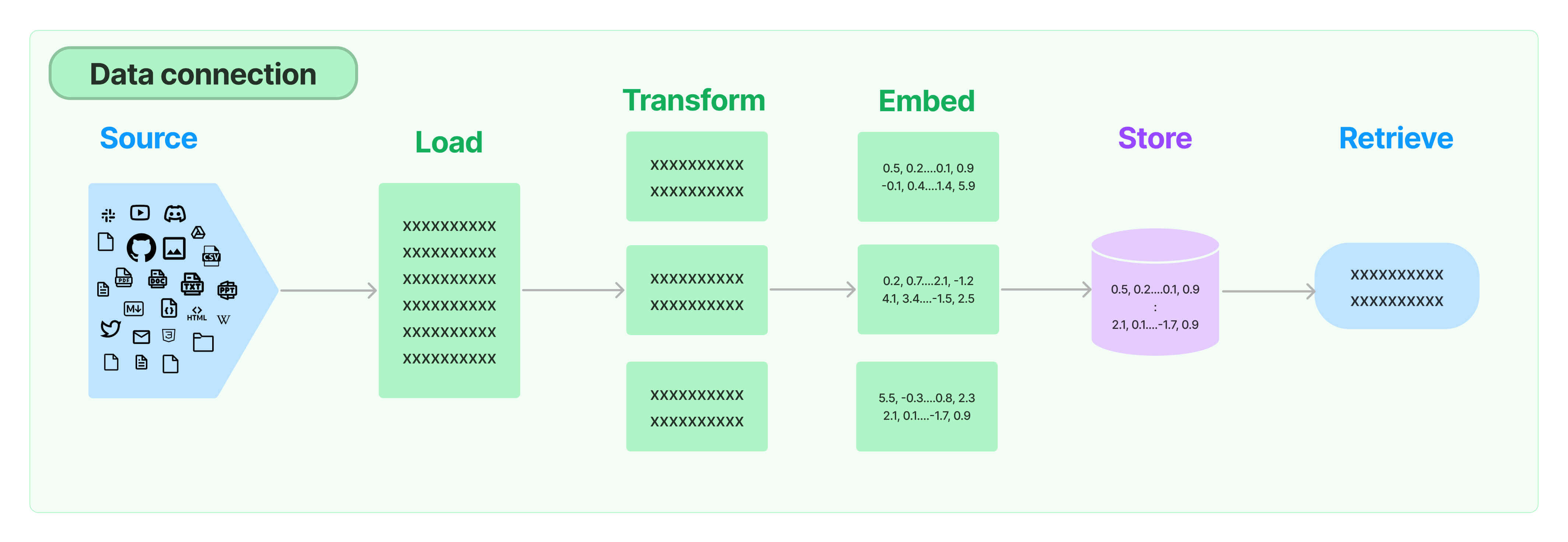
And then it goes on to describe how LangChain solves these steps.
But it doesn't really define these steps.
So let's start with the basics.
What is an LLM?
What is RAG?
Large Language Model (LLM)
LLM stands for Large Language Model, a technology in which an AI becomes very "intelligent" and useful simply by being an auto-complete machine learning mechanism trained on trillions of data points, to the point it develops enough shortcuts to seem intelligent.
When you ask for "a story about a little girl that dresses in pink", the LLM goes and basically "auto-completes" a story by figuring out what kind of text is related or is considered related to the prompt given, and it does so in a coherent way because the texts it used for education were also coherent.
A cool field, and having its bubble right now, it will pop someday and we'll be there to see it.
There are many models, commercial and open source.
Personally I'm familiar most with OpenAI's GPT models and Anthropic's Claude.
You might have heard of Facebook's LLaMA, and there are also many other open source ones.
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation.
The LLM generates text based on the prompt given to it. As in the example above "a story about a little girl that dresses in pink".
But what if you wanted to give it more context?
"A story about a little girl that dresses in pink, named {{ name }}."
What if in your DB you have different girls' names, and you want to use a different one depending on the current active user?
That's what RAG is.
For this simple example, for each user we'd fetch the user record, and get the name, and inject it in there. So some variations of the prompt would be:
- "A story about a little girl that dresses in pink, named Jenny."
- "A story about a little girl that dresses in pink, named Stacy."
- "A story about a little girl that dresses in pink, named Maria."
In other words, before you send your prompt to the LLM so it goes and does its deep neural network magic, you retrieve the most relevant data for the prompt, so that the prompt is as accurate and pertinent as it can be.
Applications vary, but common use cases include searching content and fact retrieval via Q&A.
Why RAG?
Couldn't I just give ALL the data to the LLM in the prompt, it's intelligent enough to figure it out, right?
Well, no. It's not intelligent.
And there's context window limits. If your limit is 128 tokens (each one is roughly 4 characters, depends slightly on the model), you can't fit your entire database in there, plus the system prompt, plus the generated output. At least in most cases.
Some LLMs like Claude are trying to break these barriers. But it's not cheap. And putting all of that content in the prompt will bias Claude's output.
Pro tip: rely as little as possible on the LLM being accurate, because it can be very inaccurate, randomly.
Overall for these reasons, for the use case of to improve the quality of the generated text, by augmenting the LLM's prompt with precise data, RAG is still the preferred method.
With that understanding in mind, let's move forward and talk about the steps described by that LangChain diagram.
Two phases: Preparation and Retrieval
Generally I think of the whole flow as two phases:
Preparation and Retrieval.
In Preparation we usually have:
- Source
- Load
- Transform
- Embed (of the data)
- Store
And in Retrieval we usually have:
- Embed (of the user's prompt)
- Retrieve
And finally, what we're usually building up to, although an optional step:
Preparation: Source
Your Source is anything. Video, audio, text, images, PDFs, Word docs, what have you.
These contain text of some sort, which you've got to extract in one way or another, to make useful for later in the process.
It could also be images or other media associated with the text that you're going match against.
Preparation: Load
In this diagram it is called Loading. I think of it more as Extraction the text.
The purpose of this step is to get some raw text from your Source.
Depending on the source, you may need to apply special algorithms or methods to extract the content uniformly and as cleanly as possible.
If you wanted to search over a video's contents, Loading could mean transcribing the video for example, so then you have its text to work with an LLM.
Popular tool here is Unstructured. Personally I've used it for PDFs and it does an OK job of structuring the data, although PDFs as a format are very dirty.
| Input |
Output |
| Anything |
Text |
Preparation: Transform
Now you have your raw text data.
Now you need to Transform it into useful chunks.
The usefulness of the chunk is primarily defined by whether it represents an independent "fact".
Essentially you need to split your data up into the smallest individual chunks of information that are useful for your application, or you could combine multiples of them (have the smaller chunks, and make up larger chunks from the smaller ones too). Depending on what's valuable for your application.
A chunk might be something like any of the sentences here:
Now you have your raw text data.
Or it could be longer, a paragraph:
Essentially you need to split your data up into the smallest individual chunks of information that are useful for your application, or you could combine multiples of them (have the smaller chunks, and make up larger chunks from the smaller ones too). Depending on what's valuable for your application.
But it always represents one unit of data that would be useful for your users, or to educate the prompt which then your users will find value in its generation
You need to experiment and find out what kind of chunks produce the kind of output your application needs for the user prompts that you allow or expect.
For example you could ask an LLM to split it up semantically for you, but that's expensive. Or you could split it up by sentence and associate some metadata (like the page number) and then use the whole page as reference, that's cheap, but it also might not be what you're looking for.
The single-most useful resources I have found are these, to give you some examples of how to work through a set of text to split it up:
| Input |
Output |
| Text |
Chunks of independent text |
Preparation: Embed
This is a straightforward step to do, but it will require some explanation to understand it.
In short, you are taking one of the chunks that you've split up in the previous Transform step, and assigning it weights based on a particular LLM's algorithm.
To really understand what this is about, I suggest you read this article from OpenAI's article on the subject of text and code embeddings. It has simple aesthetic visuals to really help you understand what it means to "embed" something.
THIS STEP IS OPTIONAL. It's worth noting. If you don't need semantic search capabilities, this step does not offer you value.
Options for this are OpenAI's algorithms or Claude's recommendation of VoyageAI, both hosted, or open source solutions that run locally.
# Example using VoyageAI
def embed(text: str) -> list[float]:
return vo.embed([text], model="voyage-2", input_type="query").embeddings[0]
chunk = "The Sony 1000 is the newest iPhone from Sony."
embedding = embed(chunk)
| Input |
Output |
| Chunk |
Embedded chunk (array of vectors) |
Preparation: Store
Storage and Retrieval are both straightforward. Embedding, storing, and retrieving are so closely coupled that it's tricky to speak about them in different sections.
Storage boils down to:
How and where are you going to store your embeddings and associated metadata?
Your choice will impact the following:
- Your development experience
- How you can retrieve embeddings
- What kind of metadata you can store with your embeddings
The choice boils down to specialized vector databases and traditional databases with vector support.
| Input |
Output |
| Embedded chunk |
Record in the database |
Why your database needs vector support
The necessity for vector support isn't for storage, but rather for retrieval. Storing vectors is easy, just JSON stringify them and store the JSON string.
But for retrieval if the database doesn't have vector search support, searching for a vector match would require some code akin to the following pseudo-code:
iterate through batches of records with vectors from DB
for each batch
for each record
turn the JSON into a list/array in your language
run a proximity match algorithm
if the match is good enough for your use case, add to matches
sort matches
get first X matches
As you can see this is an O(n) operation, as you have to process all of your records one by one for a match, in your application code.
Specialized vector databases
This might be what you need for seriously large amounts of vectors, in the order of millions, purely from a cost and performance perspective.
In addition these were the only real option you had, before traditional DBs got vector support added.
Hosted:
(Self-)hosted:
You'd probably run these databases in addition to your traditional database, just to store the vectors.
As you might guess, this adds complexity to your setup.
Traditional databases with vector support
This means either MongoDB or SQL databases, with added vector support.
MongoDB has official support since last year (2023) with Atlas Vector Search, I haven't had a chance to use it.
For SQL we have some options depending on our SQL flavor of choice.
Let's talk about metadata
So far we've just been talking about plain chunks, like the raw text from the content we're transforming. But we often need metadata to make these things useful.
The utility of objects
At this point it will actually be useful for you to start using objects.
If I were to use Python, I'd recommend either Pydantic or the built-in TypedDict, but otherwise you probably will need to start associating data to the chunk.
import pydantic
class Chunk(pydantic.BaseModel):
text: str
embedding: list[float]
Metadata in the chunk itself
In preparing the chunk for embedding, you don't necessarily have to include only the raw data. You could include metadata into the chunk itself as well.
E.g. if you have the following chunk:
The Sony 1000 is the newest iPhone from Sony.
You can actually play a trick with the LLM, and make it include certain data in its processing, without actually making it part of the chunk.
For example:
popularity_description = "Very popular."
release_date_description = "Released recently."
text_to_embed = f"The Sony 1000 is the newest iPhone from Sony.\n{popularity_description}\n{release_date_description}"
embedding = embed(text_to_embed)
chunk = Chunk(
text="The Sony 1000 is the newest iPhone from Sony.",
embedding=embedding,
)
You see we included some extra information in the chunk we will embed, separate from the actual text that the chunk is.
This allows the user's prompt to match more accurately for certain phrases (for example if the user includes the word recent in their prompt).
| Input |
Output |
| Text |
Chunks of independent text (with metadata) |
Metadata to accompany the chunk
In reality, at this point you probably don't want to just export chunks from this step. You actually want to export dictionaries of data, one of the bits of which is a text chunk.
For example if you're transforming a PDF file into chunks, you might have an object like this one, which includes some metadata like the page number or the paragraph number in relation to the whole PDF:
import pydantic
class PdfChunk(pydantic.BaseModel):
text: str
page_num: int
paragraph_num: int
embedding: list[float]
We will explore the utility of this later.
Example with Django and PGVector
We'll talk about metadata's value in retrieval more in detail later, but you can see in this example how we can actually easily embed our data into our Django model, and we can also include metadata like the page_num and the chunk_num.
from django.db import models
from pgvector.django import L2Distance, VectorField
class PdfChunk(models.Model):
text = models.TextField()
page_num = models.PositiveIntegerField()
chunk_num = models.PositiveIntegerField()
embedding = VectorField()
text = "Lorem ipsum."
chunk = PdfChunk(
text=text,
page_num=3,
chunk_num=100,
embedding=embed(text),
)
chunk.save()
# Later, when retrieving
user_prompt = "lol"
user_prompt_embedding = embed(user_prompt)
top_chunk = (
PdfChunk.objects.annotate(
distance=L2Distance("embedding", user_prompt_embedding)
)
.order_by("distance", "order")
.first()
)
Retrieval: Embed
In the same way that we had to embed our content, we need to embed the user's prompt.
In this way, we get a mathematical representation of the user's prompt, that we can then compare to the chunks in our database.
This does not differ from the embedding above.
user_prompt = "What is the Sony 1000?"
embedding: list[float] = embed(user_prompt)
| Input |
Output |
| User's prompt |
Embedded user's prompt (array of vectors) |
Retrieval: Retrieve
Now you have embeddings in your database, with associated metadata, and you have your user's prompt's embedding as well.
Now you can query your DB for similar embeddings.
In essence, you're just running maths on your various embeddings (vectors).
You're trying to figure out the distance between one embedding and another. The smaller the distance, the more similar, and thus the more relevant they would be considered.
Once you have the most relevant embedding(s), you also have the associated text you initially embedded (hopefully) and you have also any related metadata.
With that you can finally give something useful to your user.
You could return the content as-is, which could be useful as well, or run it through one more step, generation.
| Input |
Output |
| Embedded user's prompt |
👇 |
| The chunks in your database |
👇 |
|
Relevant chunks |
Fetching context for the top match
If you have metadata, like for example the page number or the paragraph number or something like that, you could actually then fetch those related records.
For example you could do something like this to have the most relevant chunk and the surrounding chunks, which could be useful depending on your use case:
from django.db import models
from pgvector.django import L2Distance, VectorField
# Where the model looks like
class PdfChunk(models.Model):
text = models.TextField()
page_num = models.PositiveIntegerField()
chunk_num = models.PositiveIntegerField()
embedding = VectorField()
# We could do something like
user_prompt = "lol"
user_prompt_embedding = embed(user_prompt)
top_chunk = (
PdfChunk.objects.annotate(
distance=L2Distance("embedding", user_prompt_embedding)
)
.order_by("distance", "order")
.first()
)
surrounding_chunks = (
PdfChunk.objects.filter(
chunk_num__gte=top_chunk.chunk_num - 2,
chunk_num__lte=top_chunk.chunk_num + 2,
)
.order_by("chunk_num")
.all()
)
context_text = map(lambda chunk: chunk.text, surrounding_chunks)
Of course there are many ways to work the magic of finding the most relevant chunks.
Generation
This is the step that I think people are most familiar with. It's the use-case you see when you use ChatGPT or when you've heard of any generative AI use-case.
So let's say the user asked us:
We'd depend on the model's base knowledge in order to answer this question generatively without RAG.
With RAG, the same question would be filled with real context and real answers.
Our flow looking roughly like this:
# retrieval
embed the user's prompt
check our RAG database for relevant text based on the user's prompt
we find our top chunk
# generation
we ask the AI to please present the information in a user friendly way based on the data in the chunk
Notice we don't use the user's prompt during the generation itself, only for the RAG.
Security, private vs. public applications
Private = Only a limited amount of trusted users will access it.
Public = A limited or unlimited amount of untrusted users might use it.
For public applications you never want to include the user's prompt directly into the prompt for the generation.
For a simple reason: There is no good way to safeguard against bad actors.
In private applications the use case assumes that there won't be bad actors, and if there are the damage will not be widespread.
In conclusion
I hope that was useful. I've explained to you how the full picture looks on the full stack, from data → DB → prompt.
This information will outlive the daily changes to the meta, because these are the fundamentals.
Misc.: Should I use LangChain?
In my opinion, no.
You tie yourself to an ecosystem in exchange for some syntax sugar. Bad trade.
Thus I had to do all of the above research on my own, and figure all these things out through experimentation.
Further reading
The Illusion Intelligence by Baldur Bjarnason.
He actually researched the subject, while I only had intuitions about it. His findings seem to match my understanding on the matter.
]]>


























{kind=link}